Live Updates: Post Numbered as #1 3/12/17
Hello world
Having a post ready by Sunday evenings is something I want to make a habit of. Habits are made by routinely doing something, so I should begin routinely doing it to get started. Nothing that I write is ever publication ready, but when does that ever really matter? It’s like training for a marathon. If you don’t even start training, how can someone even finish? The hardest part is sometimes just putting on your shoes in the early dawn of morning. The analogy here is, putting pen to paper, or finger to keyboard. It’s Sunday night. I just drank a cup of coffee, and I have nothing planned for tomorrow. Here are somethings I want to get done, and I guess I can try “live blogging” while doing it. A quick internet search reveals web pages comparing this to live television.Wikipedia reads:
“A live blog is a single post which is continuously updated with timestamped micro-updates which are placed above previous micro-updates.”
So, it’s “timestamped micro-update and tonight, I’m going to water my plants. Just kidding, but tomorrow I have to make a judgment call on the stuff germinating. I don’t know what unmoist soil looks like exactly, but that’s a topic for another day. Tonight, my to do list.
1: I have 1, 2 drafted blog posts I want to actually properly post. One’s the previous one before this on worms and vermicomposting which is still titled with “Draft” in its name.The other is a somewhat-long post on the vim editor that’s been sitting in my draft folder for.. over 12 months. If there’s a 3rd it would be the one on trajectory path planning, but for now, let’s just edit and make the worm blog post reader ready. I have a couple of videos posted on my vimeo account, but the free version limits me to 500 MB uploads per week. Enough for a 4 minute video. There are some bandwidth related adjustments I need to do. If you’re reading this, understand that bandwidth is money. These textual words, and pixels that make up images all cost bandwidth; and yes, bandwidth is money. So, I’m using a 3rd party service to host videos, and I’ve been deciding on how I should do images. The current hosting provider changes the tier pricing for this website sometime around mid-November, or early-November. At my pricing plan, I’m paying for about 10 Gbs upload/download regardless if I use it or not. Storage itself is a variable cost, so I want smaller files if I plan to host them on here. CPU/RAM costs associated with the back end stuff is free now. Woot? I should double verify that.
Through out the last month or so, I took some videos, and photos. I need to reduce the file size on the photos, and I need to figure out how to use a video editor in order to upload stuff on Vimeo. I could use YouTube and not worry the limits on Vimeo, but I’m going through this “Anti-Google” stage right now. Notice how above it reads, “…quick internet search reveals web pages comparing…” and not, “I googled for XYZ?” I’m trying to get rid of it form my vocabulary. It’s a freedom and privacy thing, but freedom isn’t free and neither is bandwidth. So, how to upload? What to upload?
2. I want to make ISK. What is ISK? It’s “Intersteller Credits” for an on-line game provided by CCP. It’s also the abbreviation for the currency for Iceland, which is where CCP’s HQ is located in. I make the majority of my ISK through market and trading. This means, a lot of spreadsheets, and more importantly, programming. The more independent you are on information, the more money you make, but it requries some time invested on some platform that you create. In tonight’s scenario, I want to automate my API calls from eveMarketer’s API. They use “swagger.” The new* “ESI”, (is it called ESI?) also uses swagger. What is swagger? It’s this: https://swagger.io/specification At some point, I’d like to tab into the actual CCP’s ESI and get a permission token to grab data without being dependent on EVEmarketer. I learned my lesson with eve-central. They’re gone, and partially it’s because CPP started using swagger. Other websites quickly took over their market share. Right now though, I want to use something I’m familiar with, and eveMarketer’s API is almost identical to eve-central’s API.Here are their URLS
https://evemarketer.com/
http://eve-central.com/
And yes, I could just use Google Doc’s “IMPORTxml” function, but everyone and their mom does that. I’ve been using it for the past couple of years. Everyone’s spreadsheet has a backend that looks the same. I want something different. Also, I’m rebelling against Google right? And also-also, online spreadsheets is fun and all, but those function calls won’t work if you’re offline. I want a way to save API data locally, and automatically so I can start building some historical data to compare against.
====
Alright, so on topic 1. Last night, I installed a program for video editing. Humm, before I start posting screen shots I should probably go through the part on uploading images. There’s a program I had in mind for that, one that you can apparently control via command line. Let me find it..
====
Before I even start that I need to do a quick wordpres update. WP-CLI to the rescue! Good to know crayon-te-content is still working.
wp check-update
+---------+-------------+--------------------------------------------------------+ | version | update_type | package_url | +---------+-------------+--------------------------------------------------------+ | 4.8.4 | minor | https://downloads.wordpress.org/release/wordpress-4.8. | | | | 4-partial-1.zip | | 4.9.1 | major | https://downloads.wordpress.org/release/wordpress-4.9. | | | | 1.zip | +---------+-------------+--------------------------------------------------------+
wp core-update wp core-update-db wp plugin list wp plugin update --all
With that, we should have a nice a healthy wordpress.
I think that program was called image magick: https://www.imagemagick.org/script/index.php
It advertised itself as something you can control via scripts, and the reason why I’m leaning towards it is two-fold. Another blogger (am i one?) recommended it, and it is apparently already installed on debian. Simple type, “display” In a long ago conversation with @georgiecel
“[…] Sure the images are high resolution. But when it comes to my blog, I resize to a maximum of 1600 pixels on the long edge, but serve slightly smaller versions depending on display resolution. After I resize them (using Photoshop – though there are some tools out there that use the command line and do it as an automatic process, I think one was called imagemagick?) I save them at 60% quality JPEG. You’ll be surprised how invisible the loss in quality is. 60% cuts filesize down a lot without sacrificing too much quality. Then I run the images through the app ImageOptim just to cut them down about 1% more. If you go to my much older posts (like 2013 or something?) you will notice that the images are not as optimised and take up so many megabytes! [….] But yeah, no need to serve images much bigger than 1000-2000 pixels in width unless you really want to care about 4K monitors. The images on Stocksnap are given as a more raw 100% quality large size image, so that you have flexibility to play around with the image as much as you need.”
So ImageOptim is apparently some Map app and it’s offered on the web as a service. https://imageoptim.com/mac. It’s promotional material advertises itself as, “.. saving on bandwidth.” They’re talking my language now. I mean, I would save on bandwidth by not posting up photos, but then this website wouldn’t be as pretty would it? There’s also a github repository: https://github.com/ImageOptim /ImageOptim Humm.. for a Mac. I don’t use a Mac. I’ll spend some time reading through this and Imagemagick’s documentation and then decide on a strategy for script making. That, or I’ll just look up some tutorial somewhere. The goal is simple: reduce file size, keep faithful to original image.
===
What did they call it, loss-less compression? The “El Dorada” of all JPEG algorithms? Nay, jpeg uses lossy compression which is different than lossless compression. Lossy differs from lossless.
===
And now I’m looking at https://trimage.org/ “inspired” by ImageOptim. Wootness to lossless compression!
easy AF
sudo apt-get install trimage
If I were to make a real-time vision application, I wouldn’t care abouts cost. I’d care about speed. Humm.. trade-offs..
===
Cycling through the images I’m looking to upload, I realize that I don’t need to worry about blurry pixelated photos. My lame photography skills already takes care of that. It’s hard to pick out one that isn’t blurry. Capturing photos is an ability I need to put more skillpoints in.
Another way to save on bandwidth, is by not creating so many revisions that your website has to keep in storage @_@
Some picture fun. Here’s a slightly compressed image of a no-chill label.

It’s a large photo actually. The HTML to this text is actually resizing it with width=”300″ height=”169″. You, the reader are downloading the full image, but your browser reads those parameter and adjusts it locally on your screen. This probably doens’t have to happen. In fact, it doesn’t. This proves my point. Your browser is adjusting it to a lower resolution anyways, it’s a large photo to fit on screen (let alone to embed with text), and it takes up 2.5Mb even while it’s compressed. The original photo was a1 = 2,574,171 bytes and it was compressed down to b1 = 2,530,408, so 1 – c1 = 0.017 or 1.7%. Here’s a screen shot of that, a compressed screen shot.
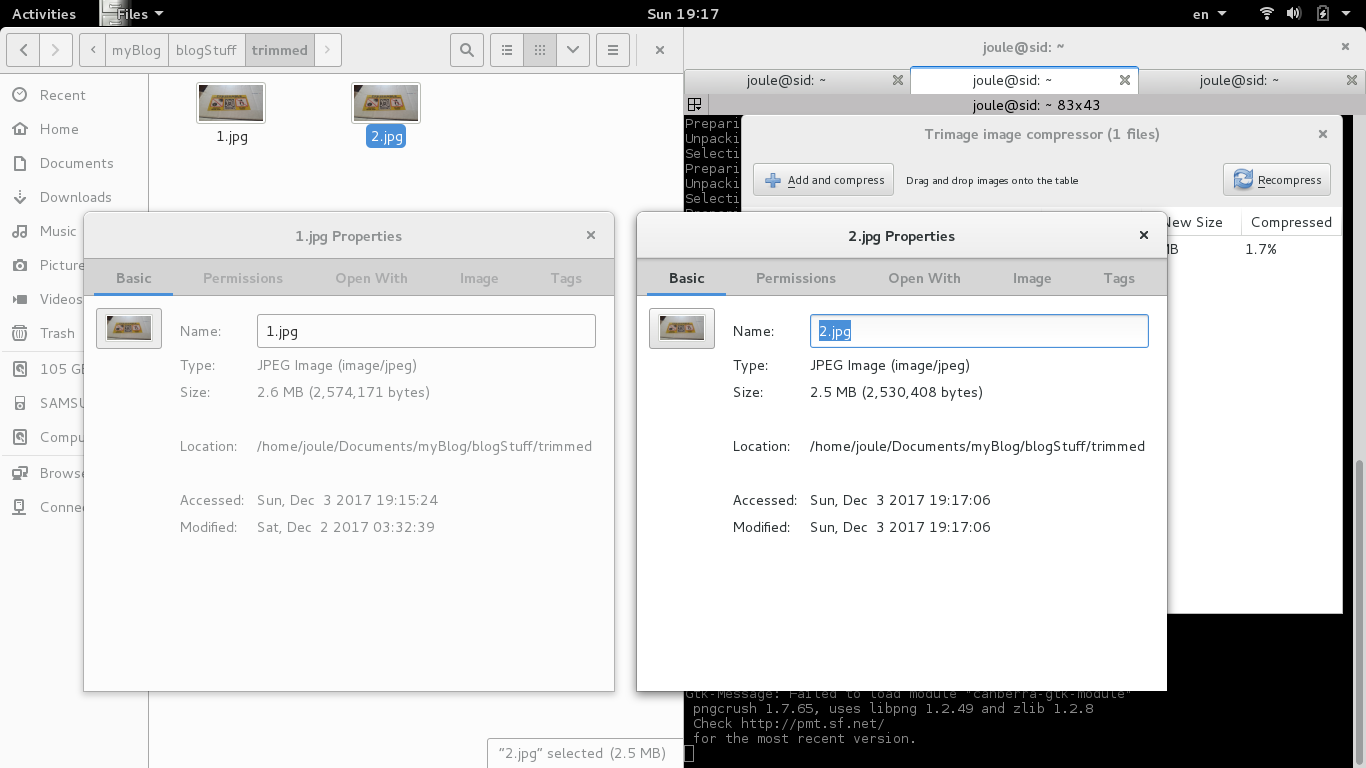
So, the program isn’t lying to you when it gives your the compression ratio. It just reads the file size before and after. I also compressed this uploaded screen shot.With a2 = 128.6 kb, and b2 = 95.4 kb, 1 – c2 = 0.25816 –> 25.8%. That’s twenty-five percent decrease. If someone offers you 25%, you say,”Yes please”. Now, the issue with the no-chill label photo is the resolution. This step is just supposed to be a final “trim” before actually uploading. I haven’t really developed a ‘style’ for how embedded images should go on this site, but seeing as the default resolution values here are width=”300″ height=”169″ that seems like a good enough start for now.
=====
There are a nummer of paths I could take right now but… https://www.imagemagick.org/Magick++/tutorial/Magick++_tutorial.pdf Scaling, rotate images, Bezier curves.. the wrapper library is strong with this one.Although, they flat out tell you (page 3) that some of the library functions don’t work.The better side of me tells me to avoid this library, but I already started reading.
The word ‘daunting’ was used. CML processing is simple though
magick logo: -resize '300x159' fileName.jpeg
That should be enough, and maybe
magick logo: -resize '300x159' *.jpeg
is enough to nuke an entire directory of photos. With the Magick++ library the function call would be
Image::zoom(const Geometry& new_geometry);
If the zoom_factor value is < 0 it zooms in, and zoom_factor is > 1 it zooms out, the image changes in resolution, but the aspect ratio pixelX:pixelY remains the same. Humm.. just for fun, let’s just go with the .cpp. Okay, here’s the plan. Install the library, and then make a makefile to.. Or, just add the library to the path, and then I don’t need to link it, er… Installing is technically the same as adding to the PATH. The MakeFile will do the same job as linking it. er…
So, yes, imagemagick is stilled on this OS, but the debian FTP version isn’t even upto date yet.
via https://packages.qa.debian.org/i/imagemagick.html CVS
but is it really fixed? Until 8:6.9.9.6 gets updated, no it’s not. They just disabled webp on that version and moved on. I admit, I’m not even using this feature, but if I take anything from this it’s that Debian won’t have upstream versions of most programs, and even now they have plenty of security issues to be concerned about. I guess I should glad they still have people looking after it, at the same time, “free software is worth every penny you pay for it.” For now, debian has version 6 offered, the makers of imagemagick are on version 7.
https://www.imagemagick.org/script/porting.php
Apparently now everything is ‘channel aware’. With version 7, commands like “convert” were replaced with simply “magick.” See above. A quick manual resizing trial quickly reduces that 2.6Mb photo down to under 25 kb. That’s significant. Now to automate it.
I want to create a c++ script that will take every *.jpg in a directory and create new resized versions of it in to x and y pixels. The program will ask for a lengthX in pixels, and an aspectRatio. The lengthY will be assumed.
identify -version
joule@sid:~/Documents/myBlog/blogStuff/trimmed$ identify -version Version: ImageMagick 6.8.9-9 Q16 x86_64 2017-11-16 http://www.imagemagick.org Copyright: Copyright (C) 1999-2014 ImageMagick Studio LLC Features: DPC Modules OpenMP Delegates: bzlib cairo djvu fftw fontconfig freetype jbig jng jpeg lcms lqr ltdl lzma openexr pangocairo png rsvg tiff wmf x xml zlib
Translation: old…
So… the authoritarian repo is on github. If i recall correctly,
git clone https://github.com/ImageMagick/ImageMagick
but, remember to cd in the directory you want to copy this in. And that takes a minute or two to finish. I’m in my programs folder, and I noticed I have Krita installed on there. I’ve been “meaning” to use it at some point. That was about, 6 months ago? Here’s the URL if anyone’s interested in that. It’s actually pretty advanced. https://krita.org/en/
ImageMagick might take more than just a minute actually. 97.57 MiB, most be a slow connection.
ImageMagick/Install-unix.txt should have everything you need to install
We can skip the “tar xvfz ImageMagick.tar.gz” step since we basically just git cloned it.
vim configure then GG tells us it has a little over 41 thousand lines of code, meh. just pretend there’s no virus in there or w/e.
Back to the install.txt, oh god. this isn’t full automated. I actually have to read through this.
Okay, so inside the repo
./configure
then skip to line 497 and that should be the rest. Maybe that was just a scare. If there’s anything to check for it’s the line
Magick++ --with-magick-plus-plus=yes yes
It should be on the output table by default. This is the feature we want to use for the c++ class wrappers. The installation seems typical now. Next is just
make sudo make install
As I microwave my dinner I verify the integrity of this install. At this point the old identify -version command above spits out a cannot access error.
make check
tells me ImageMagick 7.0.7 is installed and nothing fails. 86/86 passed demos.
but
display failsi
identify -list configure
fails also
the system isn’t able to reach shared library. the exact output is
joule@sid:~/Programs/ImageMagick$ display display: error while loading shared libraries: libMagickCore-7.Q16HDRI.so.5: cannot open shared object file: No such file or directory
some help: https://gist.github.com/wacko/39ab8c47cbcc0c69ecfb
also, the install.txt reads
On some systems, ImageMagick may not find its shared library, libMagick.so. Try running the ldconfig with the library path: $magick> /sbin/ldconfig /usr/local/lib
Again, i’m installing an a debian system, and it seems to be that the imagemagick folk have things ready for solaris/unix machines. So yeah, let’s just do that.
sudo ldconfig /usr/local/lib
and wow, it works. I don’t know why it works, but it works. <— most said line ever.
What is ldconfig? Well.. man ldconfig reads,
“ ldconfig – configure dynamic linker run-time bindings”
Alright, I’m going to eat dinner, and then I’ll do a test run on the c++ wrappers.
oh, and btw.
identify -version
spits out
Version: ImageMagick 7.0.7-14 Q16 x86_64 2017-12-03 http://www.imagemagick.org Copyright: © 1999-2017 ImageMagick Studio LLC License: http://www.imagemagick.org/script/license.php Features: Cipher DPC HDRI OpenMP Delegates (built-in): bzlib fftw fontconfig freetype jbig jng jpeg lcms lzma openexr pangocairo png tiff webp wmf x xml zlib
so, woot woot!
With it now being tomorrow, I’ll call this an end to this “live” blog.
====
If I read the word, “automagically” one more time I’m going to puke.
So, I’m going to have to make a makeFile for this.
Inside /Magick++/bin there’s a “Magick++-config” script. I’m a little confused as to what it does exactly. Is the useage output suppose to change based on the machine you’re using? Is it just a little reminder script made to bring out system variables to tell you how you should link the headerfiles? Humm.. why are the flags in backwards quotes? Backward quotes inside “double quotations” are evaluated and expressed. Ahh..
so ./Magick++-config is a shell script. The variable usage is a string variable. The batch script goes through an if, fi test. If the previous command is 0 (implying a clean exit) then it echos the string variable “usage” and it exits. The $# variable is peculiar though. The first few lines of the script are below.
#! /binsh
#
# Configure options script for re-calling Magic+ compilation options
# required to use the Magic++ library.
#
#
prefix=/usr/local
exec_prefix=${prefix}
usage='Usage: Magic++-config [--cppflags] [--cxxflags] [--exec-prefix] [--ldflags] [--libs] [--version]]
for example, "magic.cpp" may be compiled to produce "magick" as follows:
"c++ -o magick magick.cpp `Magick++-config --cppflags --cxxflags --ldflags --libs`"'
if test $# -eq 0; then
echo "${usage}" 1>&2
exit 1
fi
Okay so, this would’ve been obvious to someone more familiar with shell scripts. Above, in “if test $# =eg 0; then” the test, is actually a program called test.
man test
yeah..
Today my complier of choice is g++. By putting in the backquoted string portions into a command terminal, we get something that’s expected, path variables. Referring back to the Magic++_tutorial.pdf linked above, in page 3, under the subtitle “Using the Magick++ library in an application” The purpose of this script file is to help you get the LDFLAGS for your system.